We’ve all been there. You’re prepping for a demo or a presentation, someone asks “Can we see what this would look like with our Salesforce data?” and you realize your beautifully crafted demo is using boring sample tables that have nothing to do with the business. Or you’re building a proof of concept to show colleagues a new idea, and you need realistic-looking data with proper relationships, but you don’t have access to production yet.
This is a frustrating and very common task. I’ve found myself reaching for Snowflake’s sample data constantly – TPCH, TPCDS, Weather data – it’s all great for testing queries. But then comes the hard part: how do you make that sample data look like it belongs to your accounts, your customers, your business?
I used to fumble through this while prepping demos, trying to create joins on the fly that looked somewhat realistic. Of course, now we have tools like generative AI that can create synthetic data in seconds. But understanding how to use the modulo division join technique to connect sample data to real (or real-looking) business entities is still a valuable skill. It’s fast, it’s deterministic, and it gives you complete control over the distribution.
Let me show you the technique I’ve been using for years to turn generic Snowflake sample data into convincing business demos.
The Problem: Sample Data Doesn’t Look Real
Snowflake’s TPCH sample data is fantastic. It has orders, customers, line items – everything you need to test queries at scale. But when you’re demoing a Salesforce integration or showing how your new data architecture will work, nobody wants to see “Customer#000000001”. They want to see “Burlington Textiles Corp of America” placing orders.
You could:
- Manually create relationships (tedious and doesn’t scale)
- Use random joins (inconsistent and hard to reproduce)
- Build complex ETL processes (overkill for a demo)
Or you could use the modulo division join technique.
The Technique: Modulo Division Creates Deterministic Relationships
The core concept is beautifully simple: use the modulo operator to cycle through a list of accounts, distributing your sample data evenly across them.
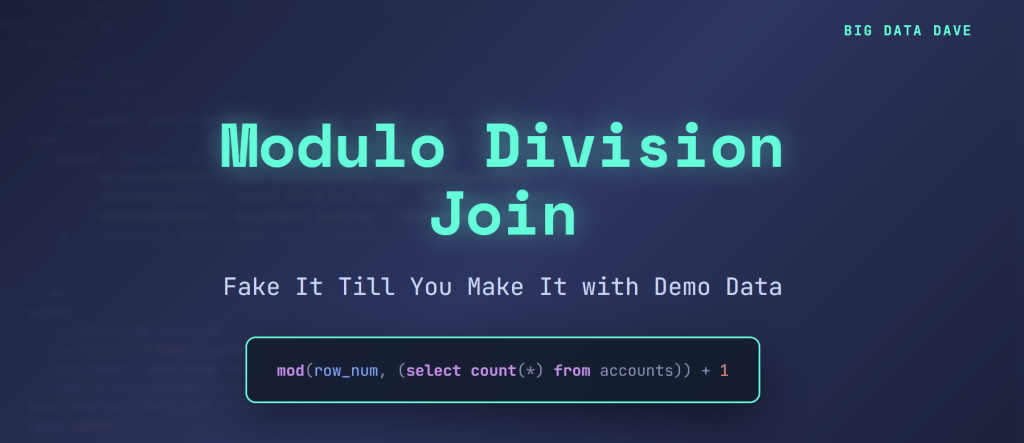
Here’s the magic line:
mod(row_number, (select count(*) from accounts)) + 1 as order_row_based_account_id
This creates a repeating sequence: 1, 2, 3, …, 50, 1, 2, 3, …, 50, and so on. When you have 100,000 orders and 50 accounts, each account gets exactly 2,000 orders. It’s deterministic, evenly distributed, and completely reproducible.
Building the Demo: Salesforce Accounts + TPCH Orders
Let me show you the complete pattern using a real-world scenario: creating a demo table that looks like Salesforce orders data for a Data Cloud federation proof of concept.
Step 1: Create Your Accounts CTE
First, we’ll create 50 fake Salesforce accounts with that classic demo data feel – Edge Communications, Burlington Textiles, GenePoint, and the crew:
with accounts as ( select account_id, account_name, account_id_18, row_number() over(order by account_name) as account_row_based_account_id from ( select * from values ('001000000000001', 'Edge Communications', '001000000000001AAA'), ('001000000000002', 'United Oil & Gas Corp.', '001000000000002AAA'), ('001000000000003', 'Burlington Textiles Corp of America', '001000000000003AAA'), ('001000000000004', 'Pyramid Construction Inc.', '001000000000004AAA'), ('001000000000005', 'Dickenson plc', '001000000000005AAA'), ('001000000000006', 'Grand Hotels & Resorts Ltd', '001000000000006AAA'), ('001000000000007', 'Express Logistics and Transport', '001000000000007AAA'), ('001000000000008', 'University of Arizona', '001000000000008AAA'), ('001000000000009', 'United Oil & Gas, UK', '001000000000009AAA'), ('001000000000010', 'United Oil & Gas, Singapore', '001000000000010AAA'), ('001000000000011', 'GenePoint', '001000000000011AAA'), ('001000000000012', 'sForce', '001000000000012AAA'), ('001000000000013', 'Acme', '001000000000013AAA'), ('001000000000014', 'Global Media', '001000000000014AAA'), ('001000000000015', 'Omega Insurance', '001000000000015AAA'), ('001000000000016', 'TechWorld Solutions', '001000000000016AAA'), ('001000000000017', 'Pacific Gas & Electric', '001000000000017AAA'), ('001000000000018', 'Northwestern Mutual', '001000000000018AAA'), ('001000000000019', 'Smith Consulting', '001000000000019AAA'), ('001000000000020', 'Johnson Controls', '001000000000020AAA'), ('001000000000021', 'Vivint Solar', '001000000000021AAA'), ('001000000000022', 'Bright Path Technologies', '001000000000022AAA'), ('001000000000023', 'CloudKick', '001000000000023AAA'), ('001000000000024', 'Red Cross', '001000000000024AAA'), ('001000000000025', 'Farmers Insurance', '001000000000025AAA'), ('001000000000026', 'Metro Bank', '001000000000026AAA'), ('001000000000027', 'National Industries', '001000000000027AAA'), ('001000000000028', 'Liberty Financial', '001000000000028AAA'), ('001000000000029', 'Summit Energy', '001000000000029AAA'), ('001000000000030', 'Cascade Manufacturing', '001000000000030AAA'), ('001000000000031', 'Heritage Healthcare', '001000000000031AAA'), ('001000000000032', 'Pioneer Technologies', '001000000000032AAA'), ('001000000000033', 'Velocity Logistics', '001000000000033AAA'), ('001000000000034', 'Atlas Consulting Group', '001000000000034AAA'), ('001000000000035', 'Horizon Pharmaceuticals', '001000000000035AAA'), ('001000000000036', 'Titan Industries', '001000000000036AAA'), ('001000000000037', 'Meridian Real Estate', '001000000000037AAA'), ('001000000000038', 'Zenith Partners', '001000000000038AAA'), ('001000000000039', 'Apex Retail Group', '001000000000039AAA'), ('001000000000040', 'Sterling Commerce', '001000000000040AAA'), ('001000000000041', 'Vanguard Systems', '001000000000041AAA'), ('001000000000042', 'Pinnacle Telecom', '001000000000042AAA'), ('001000000000043', 'Quantum Analytics', '001000000000043AAA'), ('001000000000044', 'Evergreen Hospitality', '001000000000044AAA'), ('001000000000045', 'Nova Networks', '001000000000045AAA'), ('001000000000046', 'Stellar Aerospace', '001000000000046AAA'), ('001000000000047', 'Beacon Financial Services', '001000000000047AAA'), ('001000000000048', 'Nexus Biotech', '001000000000048AAA'), ('001000000000049', 'Crown Holdings', '001000000000049AAA'), ('001000000000050', 'Vector Marketing', '001000000000050AAA') as t(account_id, account_name, account_id_18) ))
The key here is the row_number() over(order by account_name) – this gives us a sequential ID from 1 to 50 that we’ll use for the modulo join.
Step 2: Transform TPCH Orders with the Modulo Join
Now we take Snowflake’s TPCH sample data and transform it to look like realistic Salesforce orders. Notice the modulo division pattern that creates the relationship and some relevant timestamps and statuses:
orders as ( select o_orderkey as order_key, (o_totalprice/3000)::number(10,2) as order_amount, o_orderpriority as order_priority, o_clerk as service_representative, (month(o_orderdate)::string || '/' || day(o_orderdate)::string || '/2026')::date as order_date, case when o_orderstatus = 'O' then 'In Process' when o_orderstatus = 'F' then 'Cancelled' when o_orderstatus = 'P' then 'Delivered' end as order_status, iff(order_status = 'Cancelled', case when left(o_orderpriority,1) = '1' then 'Incorrect eMail Address' when left(o_orderpriority,1) = '2' then 'Invoice Format' when left(o_orderpriority,1) = '3' then 'Billing Dispute' when left(o_orderpriority,1) = '4' then 'Credit Limit' when left(o_orderpriority,1) = '5' then 'Undefined' end ,'') as cancellation_reason, uniform(1, 86400, random()) as time_offset, iff(order_status <> 'Cancelled', timeadd('second',time_offset,order_date::timestamp_ltz),null)::timestamp_ntz as order_time, iff(order_status <> 'Cancelled', timeadd('second',uniform(1, 3000, random())+600,order_time),null)::timestamp_ntz as delivery_time, row_number() over(order by random()) as row_num, mod(row_num, (select count(*) from accounts)) + 1 as order_row_based_account_id, o_comment as order_comment from SNOWFLAKE_SAMPLE_DATA.TPCH_SF10.ORDERS limit 100000)
The magic happens in this line:
mod(row_num, (select count(*) from accounts)) + 1 as order_row_based_account_id
Instead of hardcoding mod(row_num, 50), we dynamically get the count from the accounts CTE. This makes the query completely reusable – add more accounts, and the distribution adjusts automatically.
Step 3: Join Them Together
Now the join is trivial – just match on the row-based IDs:
create or replace table demo_salesforce_orders as ( with accounts as ( -- accounts CTE from above ), orders as ( -- orders CTE from above ) select accounts.*, orders.* exclude (order_row_based_account_id) from accounts join orders on accounts.account_row_based_account_id = orders.order_row_based_account_id);
What You Get
Run this query and you’ll have a table with 100,000 orders evenly distributed across 50 recognizable Salesforce accounts. Each account gets exactly 2,000 orders. Burlington Textiles has orders, GenePoint has orders, Omega Insurance has orders – and it all looks completely legitimate.
More importantly:
- It’s deterministic – run it twice, you get the same results
- It’s evenly distributed – no account gets overrepresented
- It’s fast – no complex joins or random sampling
- It’s flexible – change the account count, and everything adjusts
Beyond the Demo: Real-World Applications
While I’ve used this technique countless times for sales demos and POCs, it has broader applications:
Data Migration Testing: When you’re moving to a new system and need to test with production-like volumes but can’t use real data, this pattern lets you create realistic test datasets with proper referential integrity.
Performance Testing: Need to test how your dashboard performs with different account distributions? This technique gives you complete control over the data shape.
Training Environments: Building a sandbox for new team members? Create realistic data that looks like your business without exposing sensitive information.
The AI Caveat
Yes, tools like ChatGPT and Claude can now generate synthetic data for you. Ask for “50 fake company names” and you’ll get them instantly. But understanding this modulo division pattern gives you something AI can’t: precise control over distribution, deterministic results, and the ability to work with massive datasets efficiently.
Plus, once you understand the pattern, you can use it anywhere – not just for creating fake accounts, but for any scenario where you need to evenly distribute one dataset across another.
Conclusion
The modulo division join is one of those techniques that seems almost too simple to be useful. But I’ve used it hundreds of times over the years, and it never fails to make demo prep faster and more professional.
Next time you’re staring at generic sample data wondering how to make it look real, remember: mod(row_number, count) + 1. It’s the difference between a demo that looks like a database exercise and one that looks like your actual business.
Happy (fake data) querying!
